

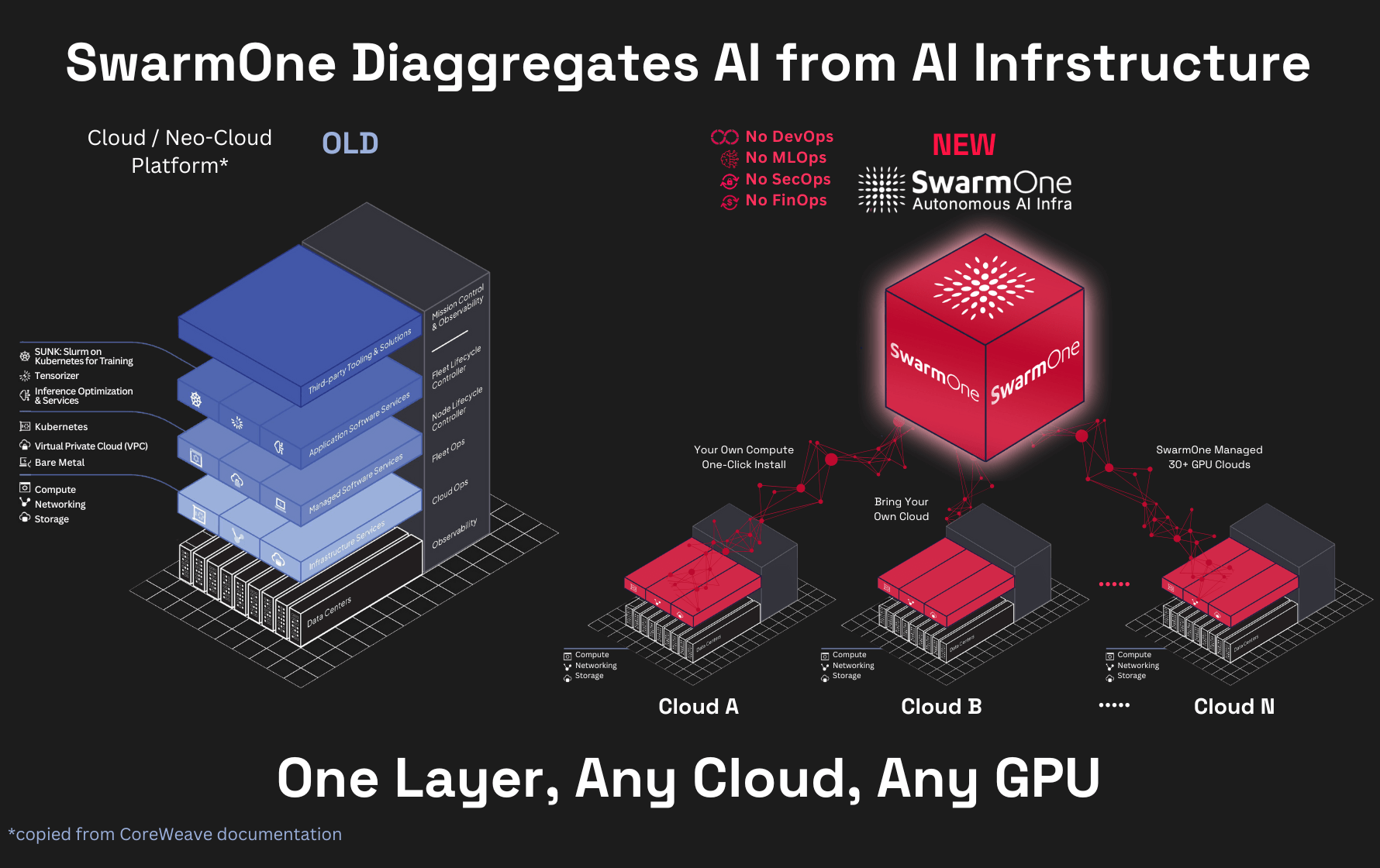
Why Kubernetes Containers Setup Falls Short for AI
AI workloads demand rapid adaptation to new models, evolving training techniques, and shifting infrastructure needs. The standard Kubernetes containers setup struggles to keep pace, leading to increased overhead for data scientists and AI engineers.
Traditional methods to configure Kubernetes containers and manage AI workloads often involve complex DevOps processes and manual configurations. While Kubernetes excels at orchestrating containerized applications, it wasn’t designed with the dynamic nature of AI workloads in mind.
The Challenges of Kubernetes Docker Setup in AI Workflows
Setting up Kubernetes with Docker introduces additional layers of complexity:
- Manual Configuration: Each change in the AI pipeline often requires manual updates to YAML files and Docker images.
- Resource Management: Allocating GPUs and managing resource constraints across different environments can be cumbersome.
- Environment Drift: Maintaining consistency across development, testing, and production environments is challenging, leading to potential discrepancies in model performance.
These challenges divert valuable time and resources away from model development and innovation.
SwarmOne vs. Kubernetes Native Setup
| Feature | Kubernetes Setup | SwarmOne |
| Setup Time | High – YAMLs and container builds required | Instant – via Python package |
| DevOps Overhead | Substantial | None |
| GPU Utilization | Manual and static | Automated and dynamic |
| Portability | Limited by config | Cloud, on-prem, hybrid with no changes |
| Error Handling | Manual debugging | Built-in error recovery |
Deconstructing Kubernetes Limitations for AI
Even advanced Kubernetes setups face the following friction points for AI:
- YAML Overload: Every model variant or environment tweak requires YAML edits.
- Container Bloat: Docker images can grow complex and hard to maintain over time.
- Elasticity Limits: Scaling is manual unless paired with additional automation layers.
These limitations become major bottlenecks in fast-paced AI research and production environments.
SwarmOne inspects your AI workload to:
- Identify necessary resources (e.g., multi-GPU, RAM, CPU).
- Automatically provision infrastructure across cloud or on-prem.
- Optimize runtime to eliminate waste and idle GPU time.
This results in dynamic scaling based on actual workload demand — not manual estimates.
Technical Integration and Architecture Overview
SwarmOne’s architecture includes:
- A lightweight Python client installed in any environment.
- Cloud-native execution layer that communicates with GPU compute infrastructure.
- Real-time orchestration of model execution, evaluation, and deployment.
This ensures AI engineers retain full control at the code level, while infrastructure adapts automatically.

Real-World Impact: Accelerating AI Workloads
Consider a research team specializing in climate modeling:
- Before SwarmOne: The team grappled with multiple containers for each model version, manual deployment processes, and fragmented infrastructure.
- With SwarmOne: They achieved streamlined training, automated evaluation, and dynamic scaling, all without manual intervention.
This transition led to a significant reduction in setup time and an increase in model performance and reliability.
Benefits of Choosing SwarmOne
- 100% Autonomy: Eliminate the need for manual Kubernetes containers setup.
- Enhanced ROI: Run up to 10x more models, maximizing GPU utilization and achieving up to 5x return on AI investments.
- Reduced Idle Time: Cut down setup and idle time by up to 84%, accelerating model deployment.
- Improved Model Quality: Experience up to a 97% increase in AI quality and performance.



